

NASSCOM Futureskills Prime Certified Advanced Data Science with Python Program including Free Internship & 100% Placement Assistance
*Data Science ranks first among the top trending jobs on LinkedIn. The future is all about Data Science & Artificial Intelligence which is helping businesses in making better decisions, tools, and a better life.
Businesses are embracing Data Science in their everyday life in order to add value to every aspect of their operations. This has led to a substantial increase in the demand for Data Scientists who are skilled in advanced technologies.
Data Science is one of the most booming sectors in the 21st century. Every sector – Cancer detection, paralysis detection, fraud and risk detection in banks, behavior analysis, Industry Automation is seeing a transformation.
Be a part of Data Science revolution with Innomatics Research Labs
PREREQUISITES:
The candidate must be pursuing a Bachelor’s degree.
Previous coding experience is an added benefit.

Languages & Tools covered in Certified Data Science Course







NASSCOM FutureSkills Prime Certified Advanced Data Science with Python Course Curriculum (Syllabus)
Your Title Goes Here
Your content goes here. Edit or remove this text inline or in the module Content settings. You can also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.
Module 1: Python Core & Advanced
INTRODUCTION
- Variables, Data Types, and Strings
- Lists, Sets, Tuples, and Dictionaries
Control Flow and Conditional StatementFunctions and ModulesFile Handling
Class and Objects
Module 2: Data Analysis using Python
Numpy – NUMERICAL PYTHO
Data Manipulation with Pandas
DATA VISUALIZATION
Data Visualization using Matplotlib and Pandas
Exploratory Data Analysis
UNSTRUCTURED DATA PROCESSING
Regular Expressions
Project On Web Scraping: Data Collection And Exploratory Data Analysis
Module 3: Advanced Statistics
Introduction to Statistics and Data Types
Descriptive Statistics
Probability Distribution
Inferential Statistics
Module 4. Data Base (SQL) + Reporting Tool (Power BI)
Introduction to SQL
Data Exploration and Data Filtering (DQL and OPERATORS)
SQL Fundamentals
SQL Database Objects
Advanced Topics
Introduction To Power BI
Data Import And Data Visualizations
Power Queries
Power Pivot And Introduction To Dax
Data Analysis Expressions
Login, Publish To Web And RLS
Miscellaneous Topics
Module 5: Machine Learning - Supervised & Un-Supervised Learning
Introduction
Validation Methods
Supervised Learning
Probability-Based Approach – Naive BayesPolynomial Regression
Introduction And Linear Algebra
Distance Based Approach – K Nearest Neighbors
Rule / Decession Boundary Based Approach – Decision Trees
Boundary-Based Linear Model – Linear Regression
Multiple Linear Regression
Evaluation Metrics for Regression Techniques
Polynomial Regression
Regularization Techniques
Logistic regression
Support Vector Machines
Ensemble Methods in Tree Based Models
Random Forest
Boosting: Adaboost, Gradient Boosting, XG Boosting:
Machine Learning Applications for Data Analysis
Un Supervised Learning
Dimensionality Reduction Techniques – PCA & t-SNE
K-Means Clustering
Hierarchical Clustering
Your Title Goes Here
Your content goes here. Edit or remove this text inline or in the module Content settings. You can also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.
Module 6: Deep Learning
Introduction to Deep Learning Principal Components Analysis
Neural Network Architecture and Activation Functions
Forward and Backward Propagation Optimizers
Neural Network Architecture and Activation Functions
Keras Hands-on – Regression and Classification
Module 7: CNN & Computer Vision
Intro to Images and Image Preprocessing with OpenCV CNN Architecture
Image Classification Case Study
Transfer Learning
Case Study with Transfer Learning
Object Detection
YOLO – Case Study
Module 8: Natural Language Processing
Introduction to text and Text Preprocessing with nltk and spacy
Vectorization Techniques
Project – Text Classification
RNNs
Project – Sequence Tagging
LSTMs
Auto Encoders
Transformer and Attention
BERT
Module 9: Gen AI
Intro To Gen AI
Intro To LLM
Prompt Engineering and Working with LLM
Open AI
Gemini
LLaMA
LangChain
Key Features of Online Data Science Training
Flexible Timings

Flexible timings for working professionals
24/7 support

24/7 One-to-one Mentorship Support
Flexible payments

Flexible Payments with Easy Installments
Life-Time Access

Life time Free access to Workshops & Seminars
We provide Online NASSCOM FutureSkills PrimeCertified Data Science training for the individuals who are occupied with work and the person who believes in one-one learning. We teach as per the Indian Standard Timings, feasible to you, providing in-depth knowledge of Data Science. We are available round the clock on WhatsApp, emails, or calls for clarifying doubts and instance assistance, also giving lifetime access to self-paced learning.
For any queries, feel free to Call/WhatsApp us on +91 9951666670 or email at info@innomatics.in
We provide Self-paced training on the NASSCOM FutureSkills Prime Certified Data Science course for individuals who are occupied with work and want to learn in their free time. We are giving lifetime access to self-paced learning. Our Self-paced video duration has 100 – 120 Hrs with Real-time practical sessions and Assignments. We are available round the clock on WhatsApp, Emails, or Calls for clarifying doubts and instant assistance.
For any queries, feel free to Call/WhatsApp us at 91 9951666670 or mail at info@innomatics.in
We provide Classroom training on NASSCOM FutureSkills Prime Certified Data Science at Hyderabad for individuals who believe in hand-held training. We teach as per the Indian Standard Time (IST) with In-depth practical Knowledge on each topic in classroom training, 80 – 90 Hrs of Real-time practical training classes. There are different slots available on weekends or weekdays according to your choices. We are also available over the call mail or direct interaction with the trainer for active learning.
For any queries feel free to call/WhatsApp us on +91 9951666670 or mail at info@innomatics.in
We provide NASSCOM FutureSkills Prime Certified Data Science training for corporates by experts, which helps businesses to strengthen and reap huge benefits. We always stay updated and provide training on real-time use cases, which bridges the gap enabling the organization to capitalize on the potential of the employees.
For any queries, feel free to call/WhatsApp us at +91 9951666670 or mail at info@innomatics.in
Advantages of Online Data Science course training?
By associating with Innomatics Research Labs, you will:
- Gain comprehensive end-to-end knowledge
- Build a strong foundation in Data Science & Data Analytics
- Gain knowledge about industry-standard tools and techniques
- Enjoy a practical-oriented teaching methodology
- Gain knowledge and understanding of statistical techniques critical to Data Analysis & Analytic models
Job opportunities in Data Science

Who Can Enroll In This Online Data Science Course?
This Data Science Course is specifically ideal for people who are
- Freshers who want to start a career, as we teach from the basics and gradually build up your skills.
- Individuals who are graduated and working in the Data Science technology field and looking to upgrade their careers.
- Analysts and Software engineers looking for a career shift in the data science stream.
Key Highlights of Online Data Science Program
- Learn from 500+ industry experts from Fortune 500 companies
- 24/7 access to a dedicated in-house data scientist team
- 200+ hours of practical, hands-on training
- Flexible online sessions on weekdays and weekends
- 5+ ongoing batches with backup classes and LMS access
- One-on-one mentorship and free technical support
- Free data science internship with real-world projects
- Work on 30+ POCs and business-based use cases
- Bi-weekly sessions with industry leaders from top sectors
- Participate in meetups, hackathons, and conferences
- Tailored programs for non-IT professionals
- Top-notch placement support
- NASSCOM FutureSkills Prime certification, globally recognized

Success Stories of Innomatics Alumni











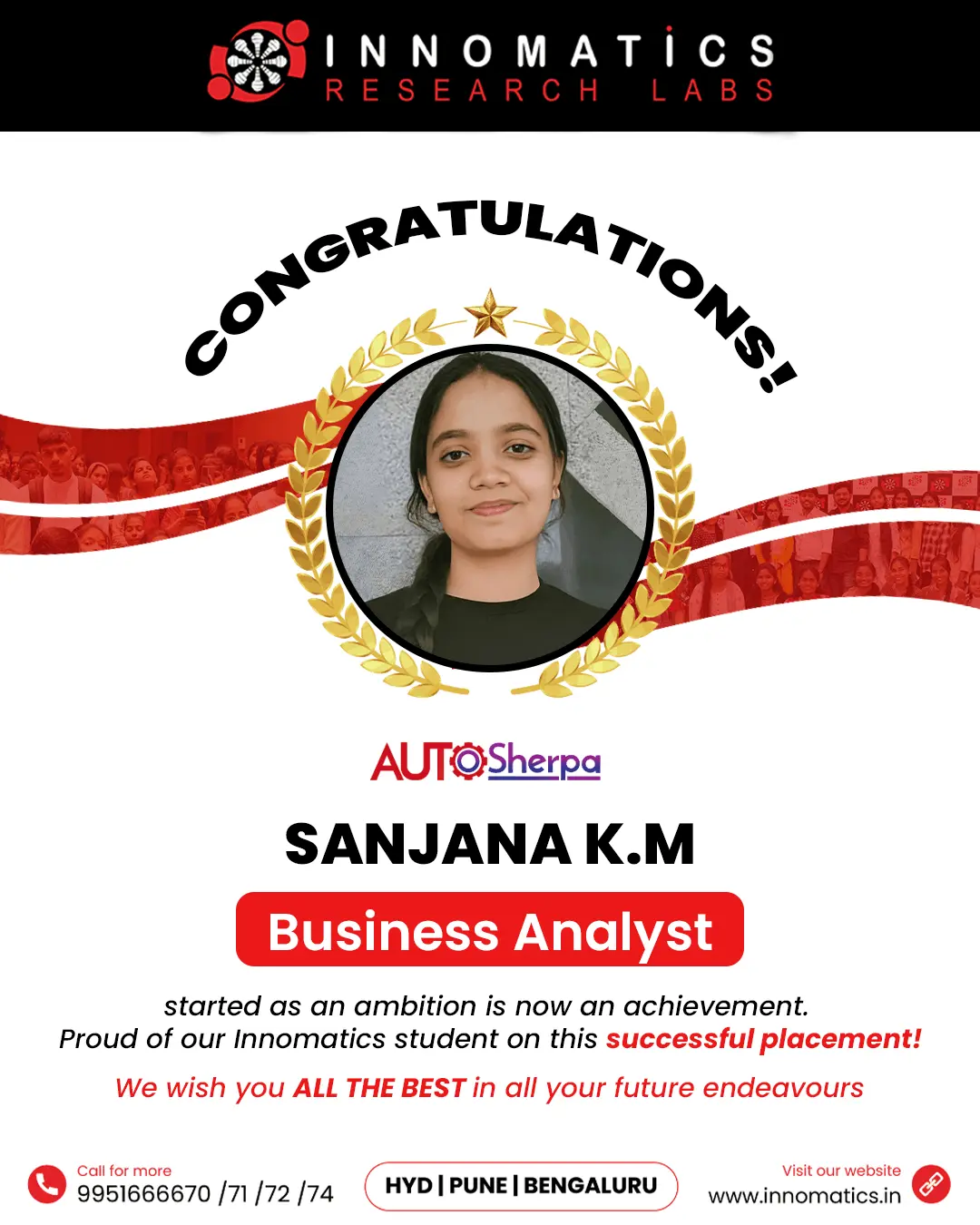











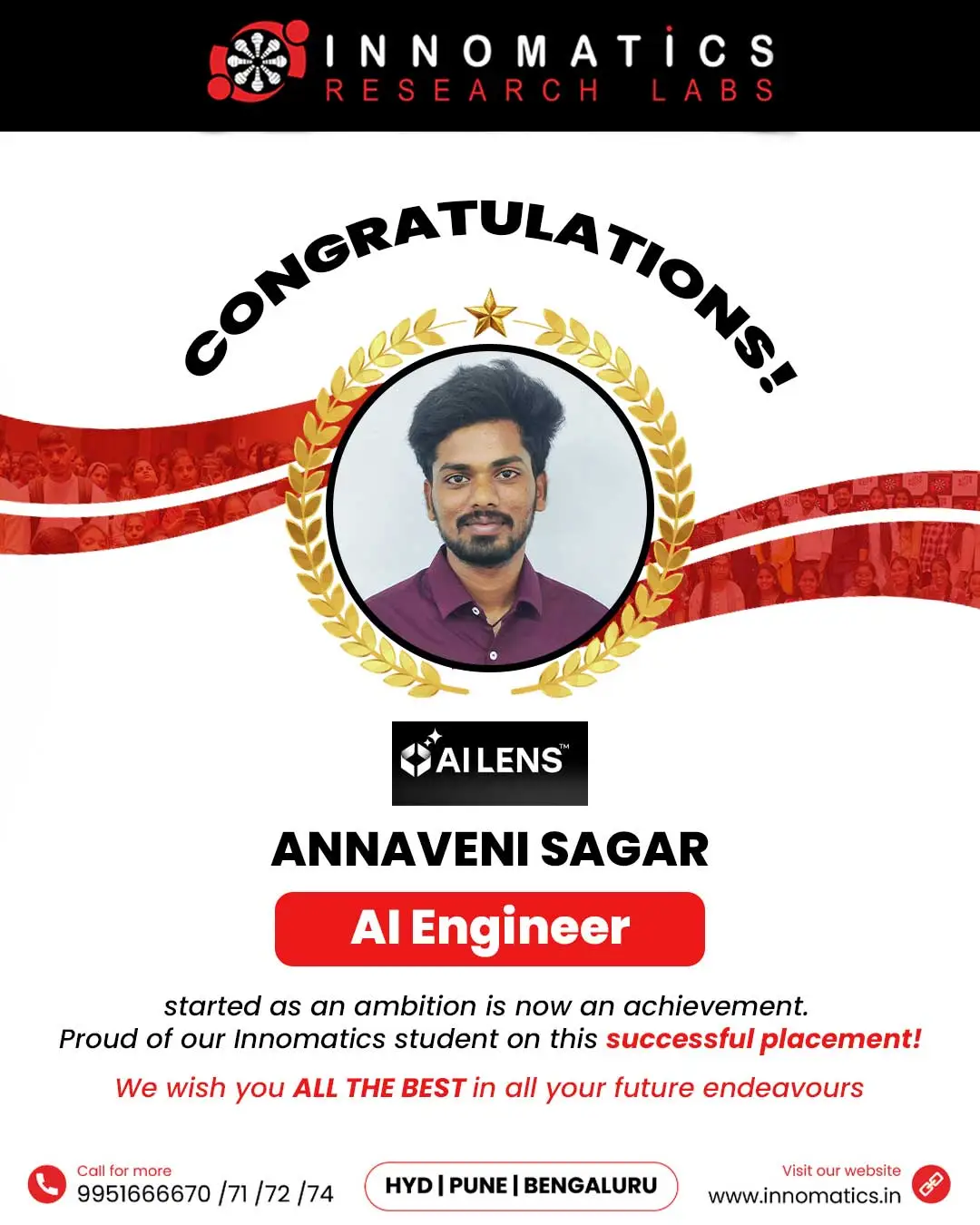









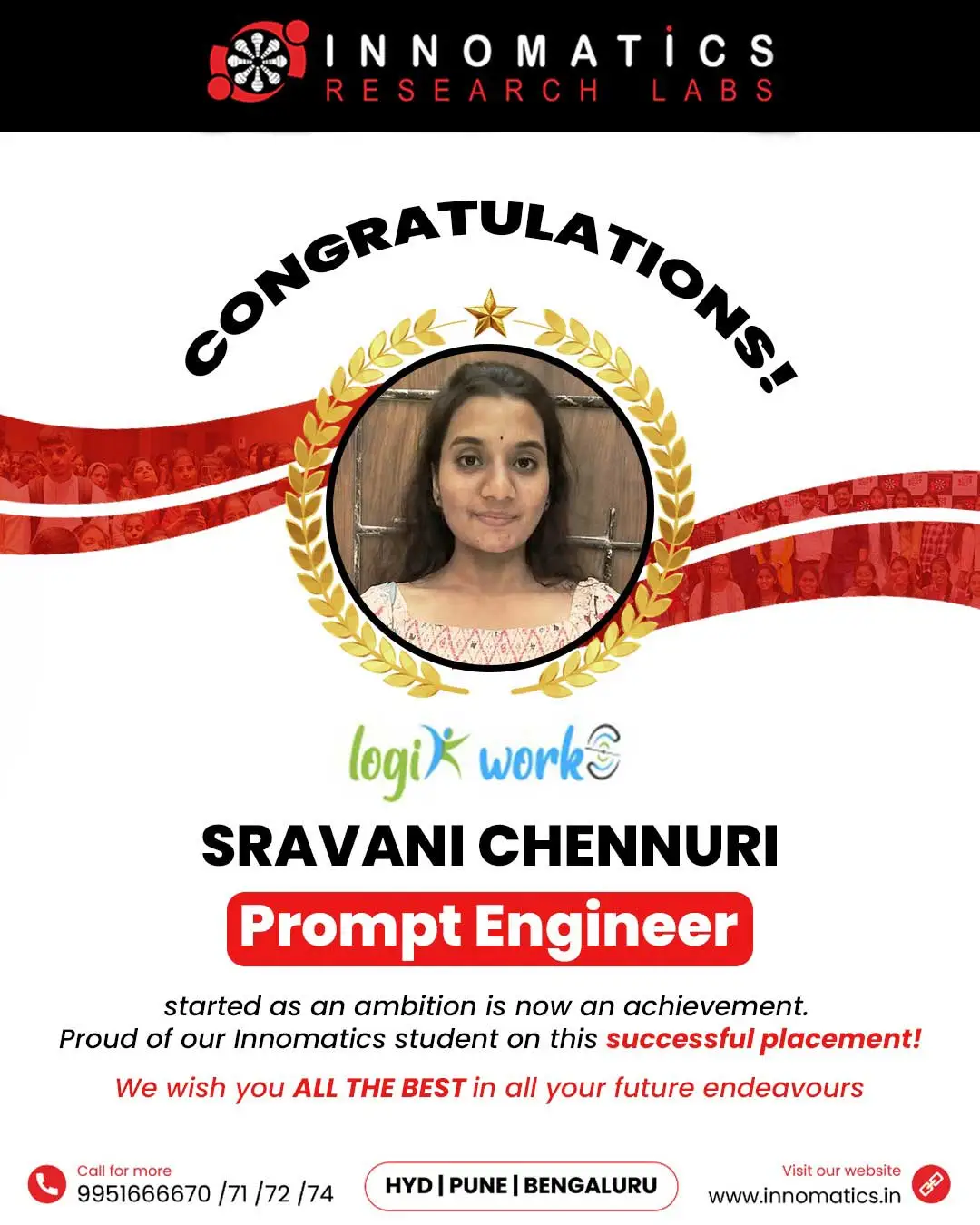
















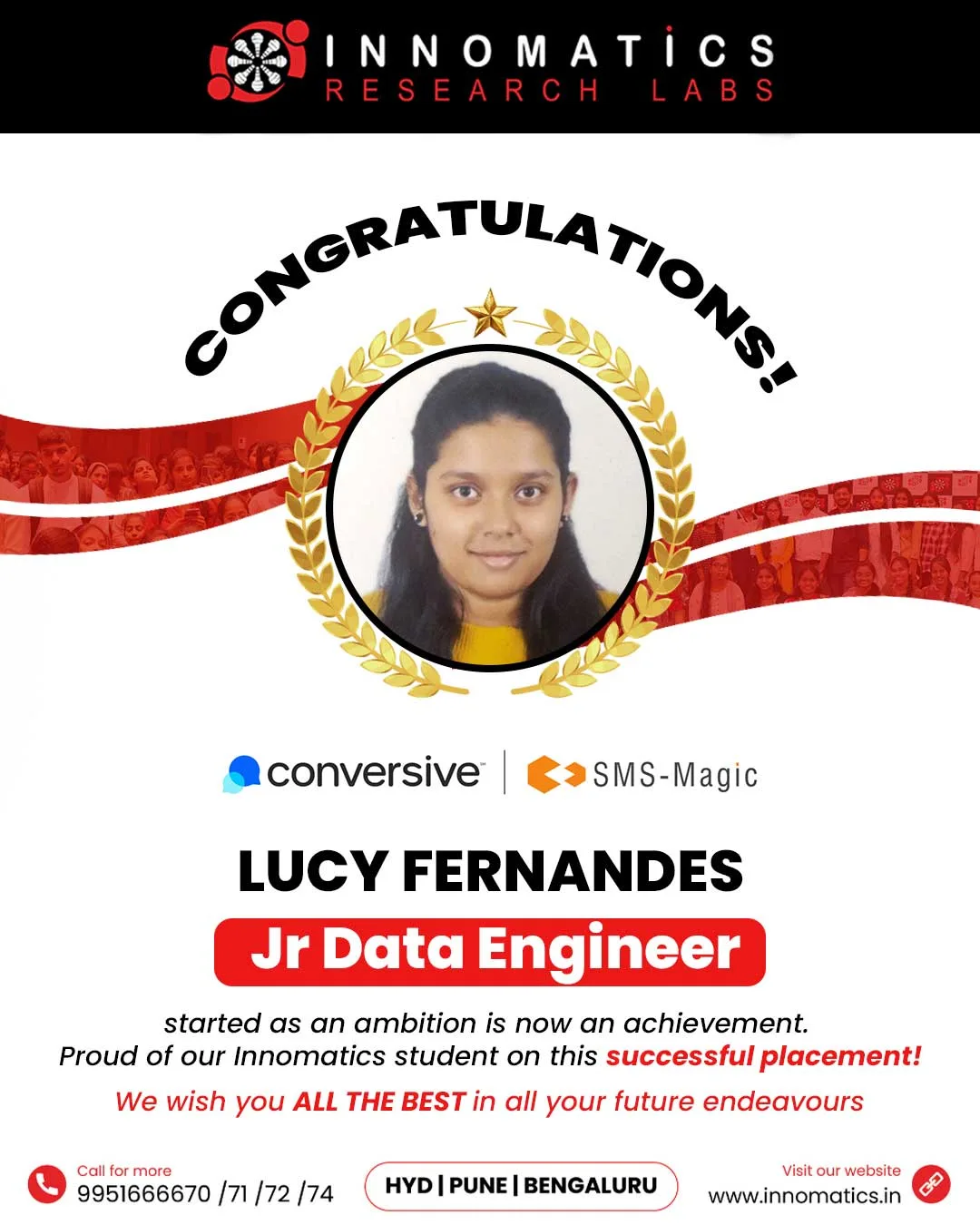













Success Stories of our Innominions
FAQs on Online Data Science Course
Your Title Goes Here
Your content goes here. Edit or remove this text inline or in the module Content settings. You can also style every aspect of this content in the module Design settings and even apply custom CSS to this text in the module Advanced settings.
Why choose an online data science course?
The best reason one could say to choose online data science course that is specially provided by innomatics is due to the flexibility of it. The online course for data science is so intuitive that you will enjoy it while doing it. Another thing is the convenience of learning at your home with the same quality that could be on-campus.
How are Innomatics verified certificates awarded?
Upon completion of the program, we will conduct the assessment, hackathons, assignments and based on the qualification in the assessment, trainees will be awarded the certification from IBM. This is a globally recognized certificate that will include over top MNCs from around the world.
What are the benefits of Innomatics self-paced Training?
Innomatics offers self-paced training to those who wants to learn at their own pace, This provides includes lifetime access to LMS where the trainees can see the backup classes, one-one sessions and queries through email. There would be an arrangement of virtual live class sessions for the trainees as well.
What do i need to do if I want to switch from self-paced training to instructor-led training?are Innomatics verified certificates awarded?
At Innomatics, the trainee can learn based on their comfort level. One can easily switch from self-paced to online instructor-led training without any extra effort.
What is the other mode so draining available at Innomatics?
Innomatics also provide Classroom Data Science Training, Online Data Science Training and Corporate Training for the employees which can upskill the workforce.
Will there be any support provided if I need assistance on the projects?
Innomatics trainers would round-the-clock and here to provide 100% assistance for all the queries that trainee raise. We are available through email or call and can also arrange a one-one session with the trainer if needed.
Do you provide any placement assistance?
Innomatics help trainees to achieve their dreams by helping trainees finding potential recruiters, resume busking, mockup interviews and helping with the entire recruiting process.
How can I choose the best specialization?
Innomatics will provide the trainees with the options that best suit them based on their background. We would suggest the best based on the role and interests. We will suggest the below based on the roles.
Data Engineering:Software and IT Professionals
Deep Learning: Engineers, Software and IT Professionals
Natural Language Processing: Engineers, Software and IT Professionals
Business Analytics: Engineers, Managers, Marketing and Sales Professionals, Domain Expert
Business Intelligence/ Data Analytics: Engineers, Marketing and Sales Professionals, Freshers